
A research team led by Professor Chang Shan from Donghua University’s School of Information and Intelligent Science has developed Baro2Talk, an innovative ear-mounted silent speech interface. The study has been accepted for presentation at IEEE INFOCOM 2026, a top-tier (CCF Category A) international conference, marking another significant milestone for the team’s work in this field.
Baro2Talk is designed to address longstanding challenges in voice-based interaction. Speech is one of the most natural and efficient modes of human–computer communication and has become a dominant input method for mobile devices, wearables, and smart assistants. The global speech recognition market is expected to grow rapidly in the coming years.
However, voice interaction remains limited in noisy environments, privacy-sensitive settings, and for individuals with speech impairments. Existing silent speech interfaces that rely on vision, wireless signals, or inertial sensors often face issues such as intrusiveness, environmental sensitivity, and complex deployment. To overcome these limitations, a new generation of silent speech technologies is emerging. By enabling speech recognition without vocalisation, these systems offer a more natural and robust alternative in situations where conventional voice input is impractical or undesirable.
The study’s core innovation lies in the discovery of temporomandibular joint (TMJ)-dominant pressure variation sequences (TPVS), which underpin the development of Baro2Talk. The researchers found that even silent articulation produces subtle pressure fluctuations within the ear canal, primarily driven by movements of the TMJ, as well as the jaw, tongue, and other oral structures. These signals exhibit consistent, repeatable patterns that encode semantic information, as shown in Figure 1 and 2. By identifying and defining these patterns as TPVS, the study establishes a foundation for modelling the relationship between in-ear pressure changes, their physiological sources, and ultimately, the intended speech content.
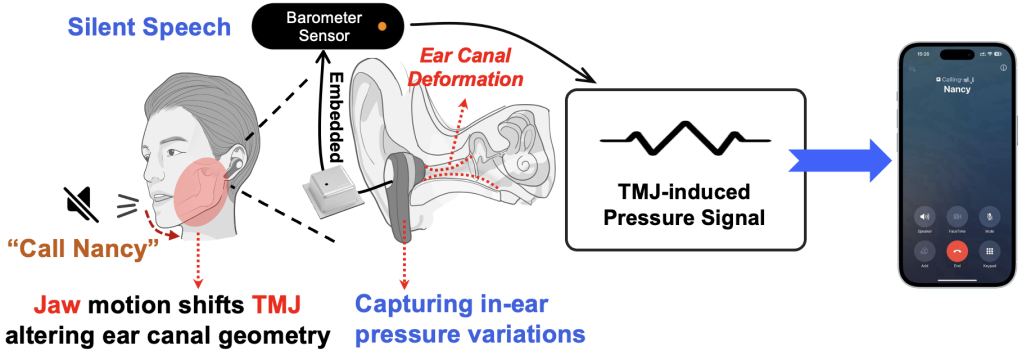
Figure 1: Conceptual diagram of Baro2Talk
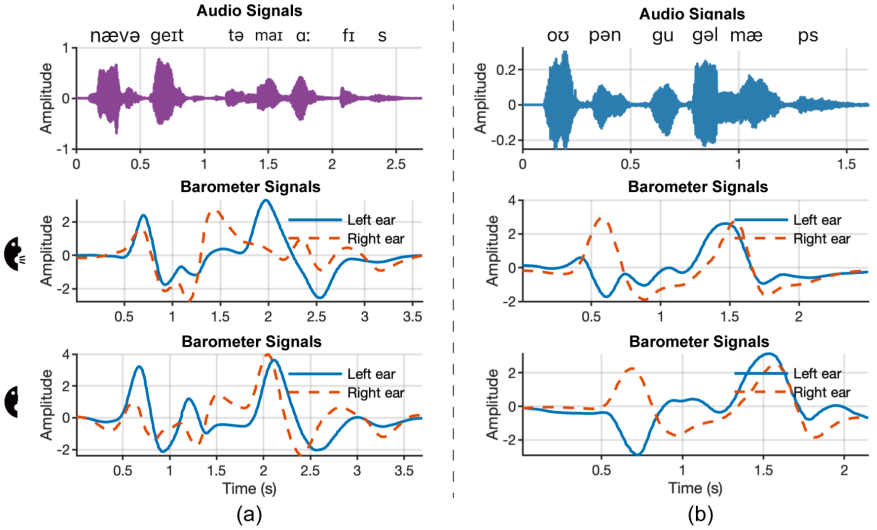
Figure 2: Example TPVS from two phrases
Following this discovery, the team embedded a miniature barometer into a standard earbud to capture TPVS signals. However, a major challenge remained: directly translating these signals into text proved difficult. The pressure data, sampled at around 100 Hz, is significantly lower in frequency than conventional audio signals, creating a substantial mismatch with high-dimensional text representations. A direct mapping would therefore require an impractically large volume of training data.
To address this, the researchers introduced Mel-spectrograms as an intermediate representation, transforming TPVS into a higher-frequency format aligned with speech characteristics. This approach preserves key features such as formants and pitch contours while bridging the gap between modalities. As Mel-spectrograms are also the standard input for mainstream automatic speech recognition (ASR) systems such as Whisper, they provide a natural interface between the pressure signals and text decoding.
Building on this foundation, the team then tackled three core technical challenges, developing targeted solutions to enable a fully functional system. The first challenge lay in the low signal-to-noise ratio and susceptibility to interference inherent in pressure signals. To address this, the team developed a preprocessing pipeline incorporating DC offset removal, band-pass filtering, and signal amplification to enhance signal clarity. They also introduced a short-term energy detection method, combined with local stability checks, to accurately extract silent speech deformation events from continuous TPVS data.
A second challenge involved variability across users and differences in speaking rates. The researchers tackled this by applying domain-adversarial learning to train a Baro-Encoder capable of extracting user-invariant semantic features, as shown in figure 3. In parallel, a rate-aware data augmentation strategy was introduced to generate time-warped TPVS variants, improving the system’s robustness to variations in speaking speed.
The third—and most fundamental—challenge stemmed from the non-acoustic nature of the signals and the absence of fine-grained supervision. Unlike conventional speech, which originates from vocal cord vibrations, TPVS is generated by internal articulatory movements and contains no acoustic energy. As a result, its spectrograms do not directly correspond to those of audio signals and cannot be mapped to them straightforwardly, as illustrated in Figure 4. This makes intermediate representations such as Mel-spectrograms essential. In addition, the lack of aligned phoneme- or frame-level labels renders traditional modelling approaches ineffective.
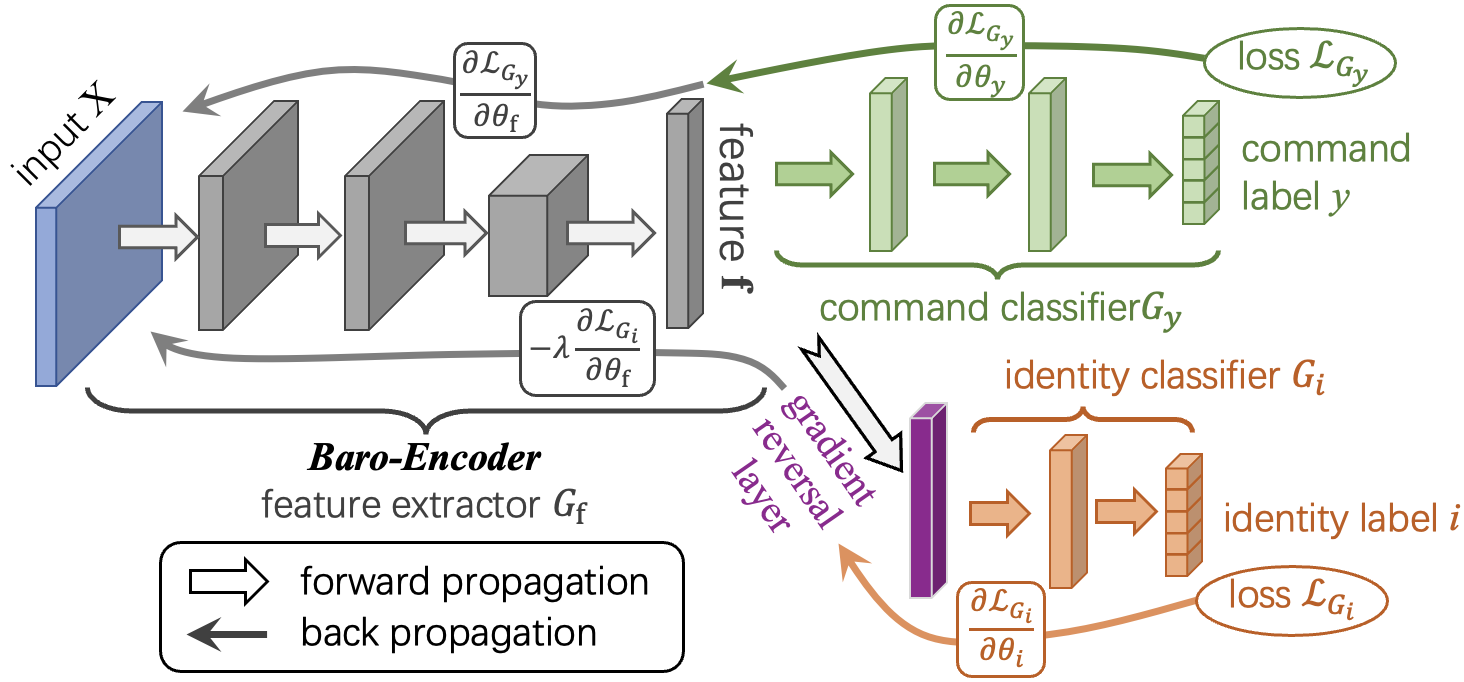
Figure 3: Diagram of adversarial pre-training for Baro-Encoder
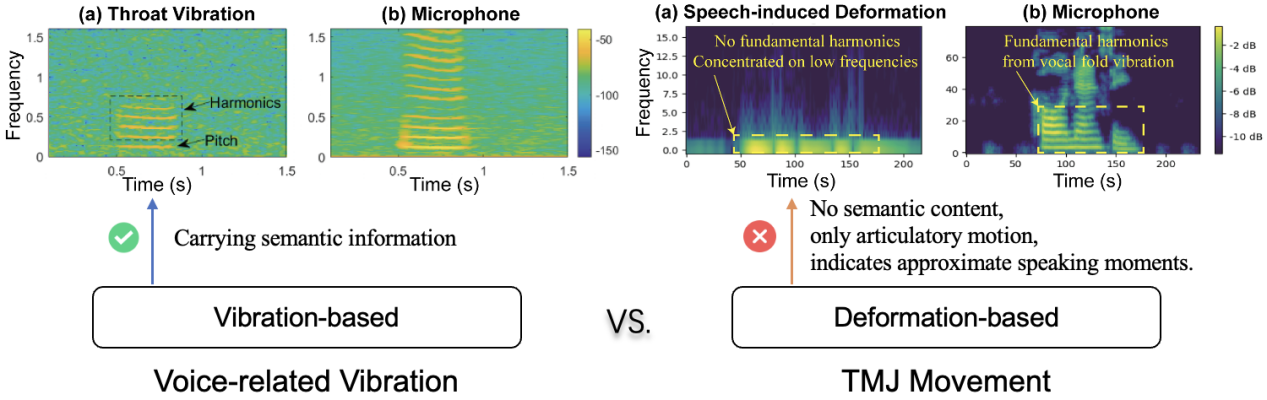
Figure 4: Comparison of Mel-spectrograms from different physiological and mechanical movements
To overcome this core challenge, the team developed a three-stage Mel-spectrogram reconstruction pipeline that separates semantic understanding from signal generation. As illustrated in Figure 5, the process begins with a semantic encoder, S-Former, which maps the full TPVS of a sentence into a latent semantic space shared with its corresponding text representation, removing the need for explicit alignment. These latent representations are then used to generate coarse Mel-spectrograms via a generative network, MS-GAN. In the final stage, the outputs are refined using PEARL (phoneme enhancement via adaptive residual learning), enabling high-fidelity reconstruction without relying on acoustic signals. The accuracy of the reconstructed Mel-spectrograms is critical, as it directly influences the performance of the downstream automatic speech recognition (ASR) system in predicting text.
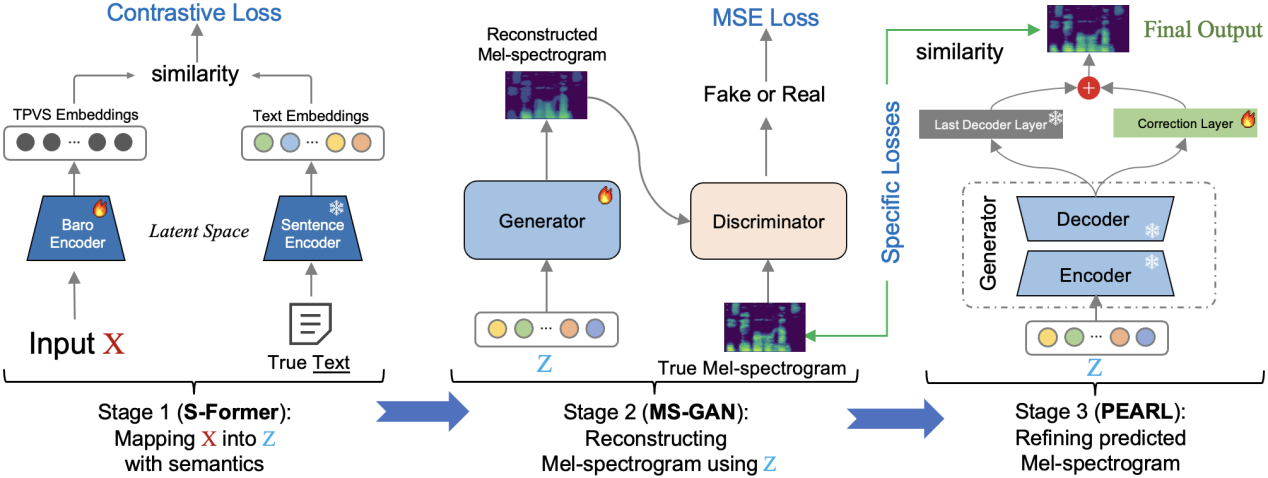
Figure 5: Three-stage Mel-spectrogram reconstruction pipeline
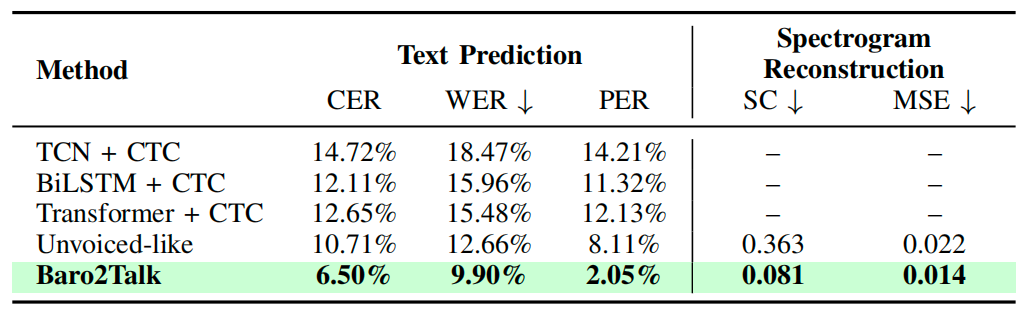
To evaluate Baro2Talk, the team compiled a dataset over six months involving 25 participants under both silent and vocal articulation conditions. Experimental results show that the system outperforms leading silent speech interface (SSI) baselines in both text prediction accuracy and Mel-spectrogram reconstruction quality, as detailed in Table 1. Further ablation studies highlight the contribution of each component within the system, confirming the effectiveness and robustness of the proposed approach.

Figure 6: Comparison of Mel-spectrogram reconstruction performance
Table 1: Text prediction accuracy and Mel-spectrogram reconstruction quality of different methods
This work has been accepted for presentation at IEEE INFOCOM 2026, a top-tier international conference designated as Category A by the China Computer Federation (CCF).